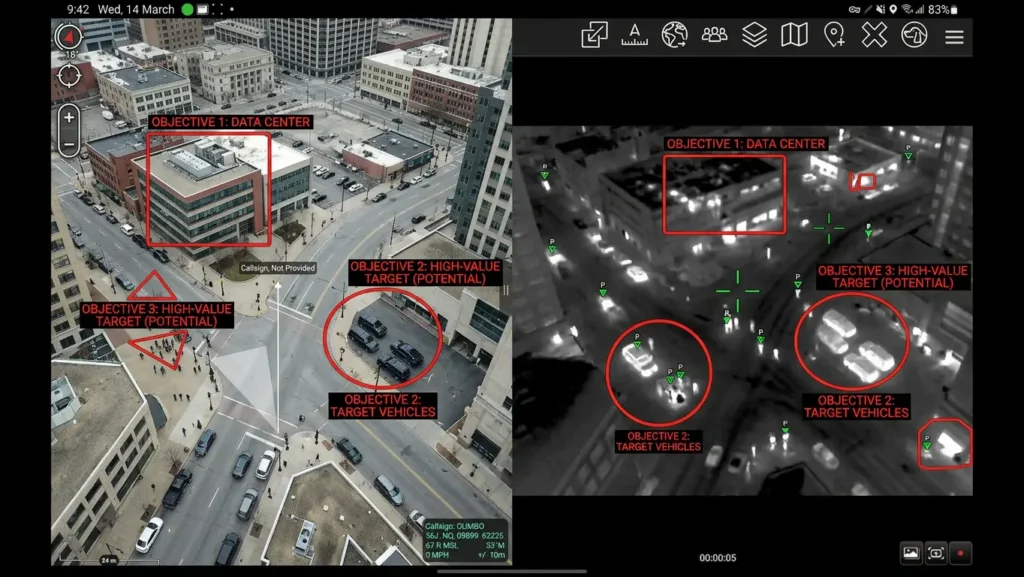
Llevas meses usando ChatGPT. Quizás también Claude o Gemini. Sabes que funcionan, que aceleran ciertas fases del trabajo y que, bien dirigidos, pueden convertirse en algo parecido a un interlocutor útil dentro del proceso creativo. Pero en algún momento te has topado con el límite: el modelo no recuerda lo que hablasteis la semana pasada, no puede leer tus propios documentos de investigación, te pide suscripción para usar las funciones que realmente necesitas, o simplemente no quiere ayudarte con algo que considera «sensible» aunque tu proyecto sea perfectamente legítimo.
Eso tiene un nombre: dependencia de plataforma. Y tiene solución.
Este artículo es para quienes ya usan IA de manera habitual y quieren dar el siguiente paso: instalar un modelo de lenguaje en su propia máquina, trabajar con él sin conexión, sin censura corporativa y sin que nadie acceda a sus conversaciones.
IA en local para artistas y creativos que quieren controlar su propio proceso.
Qué significa tener tu propio LLM
Un LLM (Large Language Model, modelo de lenguaje de gran escala) es el motor que hay detrás de ChatGPT, Claude o Gemini. Lo que hace ChatGPT es, en esencia, enviar tu mensaje a un servidor de OpenAI, procesarlo allí y devolverte una respuesta. Tú no tienes el modelo: lo estás alquilando.
Tener un LLM en local significa que ese motor vive en tu ordenador. Cuando escribes un mensaje, la respuesta se genera en tu máquina, sin pasar por ningún servidor externo. Nadie lee tus conversaciones. No hay suscripción mensual. No hay filtros corporativos que decidan qué puedes o no puedes preguntar.
Desde una perspectiva de práctica artística, esto importa por razones concretas: puedes trabajar con guiones en desarrollo sin que circulen por servidores ajenos, puedes subir documentación de un proyecto sin firmar condiciones de uso que ceden derechos, puedes explorar territorios conceptuales que los modelos comerciales bloquean por política de contenidos, y puedes construir un entorno de trabajo que sea, de verdad, tuyo.
La conversación honesta sobre el hardware
Antes de entrar en cómo hacerlo, hay que hablar de lo que nadie dice claramente en los tutoriales entusiastas: los modelos grandes necesitan máquinas potentes.
Los modelos de lenguaje más capaces —los que se comparan razonablemente con GPT-4— requieren GPUs con muchos gigas de VRAM o procesadores con gran cantidad de memoria unificada. Estamos hablando de equipos que no todo el mundo tiene encima de la mesa.
Esto no es un problema sin solución. Es una restricción de diseño que, bien entendida, te lleva a tomar decisiones inteligentes.
Si tienes un Mac con chip Apple Silicon (M1, M2, M3, M4 o versiones Pro/Max), estás en una posición muy favorable. La arquitectura de memoria unificada de estos chips permite ejecutar modelos medianos con una fluidez sorprendente. Un Mac M2 con 16 GB de RAM puede correr modelos de 7 a 13 mil millones de parámetros de manera cómoda. Con 32 GB, la experiencia mejora notablemente.
Si tienes un PC con GPU dedicada, la clave es la VRAM. Con 8 GB puedes trabajar con modelos de 7B cuantizados; con 12-16 GB, el rango se amplía considerablemente. Sin GPU dedicada o con una integrada, el modelo funciona pero la velocidad de respuesta puede desesperar.
Si tienes un ordenador modesto, la respuesta no es renunciar, sino elegir modelos más pequeños. Y aquí está la parte contraintuitiva: los modelos pequeños recientes son sorprendentemente buenos. Phi-3 Mini de Microsoft, Gemma 2 de Google o Llama 3.2 de Meta en sus versiones de 1B y 3B parámetros corren en casi cualquier máquina y ofrecen una calidad de respuesta que habría parecido imposible hace dos años. Para IA en local para artistas y creativos que empiezan, estos modelos son el punto de entrada perfecto.
Dónde viven los modelos: Hugging Face, GitHub y el ecosistema abierto
Antes de hablar de cómo instalar un modelo en tu máquina, vale la pena entender de dónde vienen. Los modelos de lenguaje que puedes usar en local no los fabricas tú ni los compras en una tienda: los descargas de repositorios públicos donde investigadores, empresas y comunidades los publican libremente.
El concepto clave aquí es modelo abierto (open source o open weights). A diferencia de GPT-4 o Claude —cuyos pesos internos son privados y solo accesibles a través de una API de pago—, los modelos abiertos publican sus parámetros para que cualquiera pueda descargarlos, estudiarlos, modificarlos y ejecutarlos. Meta lo hace con Llama, Google con Gemma, Microsoft con Phi, Mistral AI con Mistral. Son empresas que han decidido, por razones estratégicas o filosóficas, liberar sus modelos al público.
Hugging Face es el gran hub donde vive la mayoría de este ecosistema. Funciona como una especie de GitHub para modelos de IA: puedes explorar miles de modelos organizados por categoría, tamaño, idioma o capacidad, ver fichas técnicas, leer comentarios de la comunidad y descargarlos directamente. Si buscas un modelo entrenado específicamente en español, uno optimizado para código, uno afinado para diálogo creativo o uno sin filtros de contenido, es probable que encuentres varias opciones en Hugging Face.
GitHub cumple una función complementaria: es donde se publica el código que rodea a los modelos —las interfaces, los scripts de instalación, las herramientas de afinado— y donde se desarrollan proyectos como el propio Ollama o AnythingLLM. Cuando una herramienta de IA anuncia una actualización, normalmente aparece primero en GitHub.
Lo que hace especialmente relevante este ecosistema para artistas es la diversidad de lo que existe en él. Además de los modelos generalistas que replican la experiencia de ChatGPT, hay una categoría que conviene conocer: los modelos sin censura (uncensored) y los modelos afinados para usos específicos.
Los modelos uncensored son versiones de modelos base que han sido reentrenados para eliminar o reducir los filtros de contenido que los modelos comerciales aplican por defecto. No están diseñados para usos malintencionados —ese es el argumento que siempre se usa para justificar los filtros corporativos—, sino para contextos donde la restricción automática interfiere con el trabajo legítimo: escritura de ficción con temáticas adultas, exploración conceptual en zonas grises, investigación que requiere acceso a materiales que los filtros clasifican como sensibles sin distinción de contexto.
Para un artista o creativo que trabaja con narrativas complejas, iconografía perturbadora, cuerpos no normativos o discursos que cualquier filtro corporativo malinterpretaría como problemáticos, poder elegir un modelo sin esas restricciones no es un capricho técnico. Es una condición de posibilidad del trabajo.
La variedad disponible es enorme y crece cada semana. Hay modelos entrenados específicamente en literatura, en filosofía, en código, en conversación terapéutica, en roleplay creativo, en análisis visual. El ecosistema abierto no ofrece un único modelo universal: ofrece la posibilidad de elegir la herramienta que mejor encaja con el tipo de trabajo que estás haciendo.
Ollama: el puente entre el modelo y tú
Para entender por qué necesitas dos herramientas y no una sola, ayuda pensar en una analogía sencilla: el motor de un coche y el habitáculo en el que vas sentado son dos cosas distintas. Puedes tener el mejor motor del mundo debajo del capó, pero sin volante, asientos y panel de control no puedes conducir cómodamente. En el sistema que vamos a construir, Ollama es el motor y AnythingLLM es el habitáculo. Cada uno hace algo que el otro no puede hacer solo.
Ollama se encarga de la parte técnica invisible: descargar los modelos desde Hugging Face u otros repositorios, almacenarlos correctamente en tu máquina, cargarlos en memoria cuando los necesitas y servirlos de manera eficiente. Es, en esencia, un gestor y servidor de modelos. Funciona en segundo plano, como cualquier servicio del sistema, y cuando AnythingLLM —u otra interfaz— necesita enviarle una pregunta a un modelo, se la manda a Ollama, que la procesa y devuelve la respuesta.
La instalación de Ollama es la de cualquier aplicación de escritorio: descargas el instalador desde su web, lo ejecutas y listo. Funciona en macOS, Linux y Windows. Y aquí viene algo importante: no necesitas tocar la terminal en ningún momento. Ollama publica en su web el catálogo completo de modelos disponibles, con fichas de cada uno, tamaños y variantes. Cuando encuentras el que quieres usar, copias su nombre. Después, en AnythingLLM, abres el desplegable de selección de modelo, escribes ese nombre, el sistema lo reconoce y te ofrece descargarlo directamente desde la interfaz. Un clic, y el modelo empieza a descargarse a tu máquina sin que hayas abierto ninguna ventana de comandos.
Lo importante es entender que Ollama no es la interfaz con la que conversas: es la infraestructura que hace posible que esa conversación ocurra en tu máquina. Cuando AnythingLLM te muestra el chat, por detrás está hablando con Ollama, que es quien realmente corre el modelo. Separar estas dos capas tiene ventajas concretas: puedes cambiar de modelo en Ollama sin tocar la configuración de tu interfaz, puedes usar el mismo Ollama desde varias interfaces distintas, y si en el futuro quieres conectar otras herramientas —editores de código, aplicaciones creativas, scripts propios— todas pueden apoyarse en el mismo motor.
El catálogo de modelos disponibles en Ollama cubre prácticamente todo el ecosistema abierto relevante: Llama de Meta, Gemma de Google, Phi de Microsoft, Mistral, Qwen, DeepSeek, y muchos modelos afinados que la comunidad ha publicado. Para acceder a los modelos uncensored o a versiones más especializadas que no están en el catálogo oficial de Ollama, puedes importarlos manualmente desde Hugging Face: se descargan en formato GGUF y Ollama los carga sin problema.
AnythingLLM: el ChatGPT libre que vive en tu casa
Si Ollama es el motor, AnythingLLM es el habitáculo completo. Es una interfaz que se instala en tu ordenador, disponible como aplicación de escritorio, que te da acceso a prácticamente todo lo que hace ChatGPT Pro, más algunas cosas que ChatGPT no puede hacer, y sin todo ello sin el coste de una suscripción mensual.
Funciona con los modelos que tienes instalados a través de Ollama, pero también puede conectarse a modelos en la nube si en algún momento lo necesitas. La interfaz es limpia, intuitiva y no requiere conocimientos técnicos para usarla a diario. Si sabes usar ChatGPT, sabes usar AnythingLLM.
Pero lo interesante no es la interfaz en sí, sino lo que puedes hacer desde ella.
RAG: conversar con tus propios documentos
RAG son las siglas de Retrieval-Augmented Generation, que en la práctica significa algo muy sencillo: puedes subir tus propios documentos y el modelo los lee y los incorpora a sus respuestas.
Imagina que tienes tres años de notas de investigación sobre un proyecto, un dossier de artista en PDF, artículos académicos que has ido acumulando, transcripciones de entrevistas, referencias bibliográficas. En ChatGPT estándar, cada vez que abres una conversación empiezas desde cero. En AnythingLLM con RAG, subes esos documentos a un espacio de trabajo y el modelo los tiene presentes mientras conversa contigo.
Puedes preguntarle «¿qué decía Hakim Bey sobre los espacios temporalmente autónomos en ese texto que subí?» y obtendrás una respuesta basada en tu material, no en lo que el modelo aprendió durante su entrenamiento. Esto cambia completamente la utilidad del sistema para quien trabaja con investigación propia, con archivos de proceso o con corpus documentales específicos.
Espacios de trabajo separados por proyecto
AnythingLLM organiza el trabajo en workspaces, espacios independientes que puedes configurar de manera distinta según el proyecto. Cada workspace tiene su propio conjunto de documentos, su propia memoria y, si quieres, su propio modelo asignado.
Puedes tener un workspace para un proyecto de videoarte en el que has cargado el guión, las referencias visuales en texto y las notas de dirección, y otro completamente separado para el trabajo de comisariado, con su propia bibliografía y documentación. El modelo no mezcla contextos. Cada conversación ocurre dentro del espacio que le corresponde.
Agentes: más allá del chatbot
Aquí es donde AnythingLLM da un salto cualitativo. Además de conversar con documentos, incorpora un sistema de agentes que puede ejecutar tareas de manera autónoma usando herramientas externas.
Un agente no es solo un modelo que responde: es un modelo que puede tomar decisiones, usar herramientas y completar secuencias de acciones sin que tengas que ir paso a paso. En AnythingLLM, los agentes tienen acceso a capacidades como:
Navegación y scraping web. El agente puede visitar páginas, extraer información y traértela procesada. Si estás investigando artistas, exposiciones o publicaciones recientes, puedes pedirle que recopile y resuma en lugar de hacerlo tú manualmente.
Búsqueda en internet. Integrado con motores de búsqueda, puede consultar información actualizada y sintetizarla dentro de tu conversación, algo que los modelos de lenguaje base no pueden hacer por sí solos al no tener acceso a internet.
Generación y ejecución de código. Si necesitas procesar datos, generar scripts o automatizar tareas, el agente puede escribir el código y ejecutarlo directamente, no solo mostrarte el resultado.
Interacción por voz. AnythingLLM incorpora capacidades de síntesis y reconocimiento de voz, lo que significa que puedes hablarle y que él te responda en voz alta. Para quienes trabajan en estudio y prefieren no interrumpir el flujo físico del trabajo para teclear, esto tiene un valor práctico inmediato.
Gestión de archivos. Puede leer, crear y organizar archivos en tu sistema dentro de los permisos que tú le hayas concedido. Útil para gestionar exportaciones, organizar carpetas de proyecto o procesar lotes de documentos.
Los modelos pequeños: por qué son suficientes para la mayoría de lo que necesitas
Hay una narrativa dominante que equipara calidad con tamaño: el mejor modelo es el más grande. Eso era más cierto en 2022 que hoy. La investigación en eficiencia de modelos ha avanzado de manera notable y los modelos pequeños recientes tienen un rendimiento que sorprende.
Para IA en local para artistas y creativos, la pregunta relevante no es «¿es este modelo tan bueno como GPT-4?» sino «¿es suficientemente bueno para lo que necesito hacer?». Y en la mayoría de los casos de uso habituales —redactar textos, explorar ideas, editar propuestas, investigar dentro de un corpus documental, generar variaciones conceptuales, dialogar sobre el proceso— la respuesta es sí.
Llama 3.2 de Meta en sus versiones de 1B y 3B es rápido incluso en máquinas modestas y cubre bien tareas de texto generales. Gemma 2 de Google y Phi-3 Mini de Microsoft están optimizados para funcionar con recursos limitados sin sacrificar demasiada capacidad de razonamiento. Mistral 7B es un referente en la relación entre tamaño y rendimiento. Qwen ofrece variantes pequeñas con buen soporte multilingüe, lo que importa si trabajas habitualmente en español.
La estrategia práctica para quien empieza es esta: comienza con un modelo de 7B o menos, trabaja con él durante una semana y comprueba si cubre lo que necesitas. En la mayoría de los casos, lo hará. Si te encuentras con limitaciones específicas —razonamiento complejo, contextos muy largos, tareas técnicas avanzadas— puedes experimentar con modelos mayores si tu hardware lo permite, o usar puntualmente un modelo en la nube para esa tarea concreta mientras mantienes el trabajo cotidiano en local.
Privacidad, censura y soberanía: lo que cambia realmente
Cuando usas ChatGPT, tus conversaciones pueden ser utilizadas para mejorar futuros modelos salvo que hayas desactivado explícitamente esa opción. Si trabajas con material sensible —proyectos en desarrollo, documentación de personas, procesos que no quieres que circulen—, eso es una consideración real, no una paranoia.
Cuando usas un modelo en local, la conversación no sale de tu máquina. No hay servidor que la reciba, no hay empresa que la procese, no hay condiciones de uso que firmar sobre los datos generados.
La censura es otro vector relevante para artistas. Los modelos comerciales aplican filtros de contenido diseñados para el uso masivo y general, no para la práctica artística. Eso significa que ciertas exploraciones conceptuales, ciertos registros narrativos, cierta iconografía o ciertos territorios temáticos quedan bloqueados por defecto, no porque sean ilegítimos, sino porque el filtro no distingue contextos. Un modelo local no tiene esos filtros a menos que tú mismo los configures. El espacio latente está abierto.
Esto conecta con lo que en el contexto de hybridart.net hemos llamado soberanía creativa: no la independencia tecnológica como fin en sí mismo, sino como condición para que el proceso artístico pueda ocurrir sin tutelas externas. La IA en local no es una postura ideológica; es una decisión práctica que amplía el territorio de trabajo disponible.
Cómo empezar: el camino mínimo viable
No necesitas hacerlo todo a la vez. Este es el recorrido mínimo para tener un sistema funcionando:
Paso 1. Instala Ollama. Ve a ollama.com, descarga el instalador para tu sistema operativo y ejecútalo como cualquier aplicación. Una vez instalado, Ollama arranca en segundo plano de forma automática cada vez que enciendes el ordenador. No verás ninguna ventana: trabaja silenciosamente como un servicio del sistema, listo para recibir peticiones.
Paso 2. Elige y descarga un modelo desde Ollama. Antes de abrir AnythingLLM, necesitas tener al menos un modelo descargado en Ollama. Ve a ollama.com/library y explora el catálogo: verás los modelos disponibles con su tamaño, descripción y variantes. Copia el nombre del que quieras usar —por ejemplo llama3.2 o mistral—. Si no sabes por dónde empezar: Llama 3.2 3B o Gemma 2 2B para máquinas modestas; Mistral 7B o Llama 3.1 8B si tienes más recursos. Una vez elegido el modelo, abre AnythingLLM, ve al desplegable de selección de modelo, escribe el nombre que copiaste y el sistema te ofrecerá descargarlo directamente. Sin terminal, sin comandos. La descarga puede tardar unos minutos según el tamaño del modelo y la velocidad de tu conexión.
Paso 3. Instala AnythingLLM y conéctalo a Ollama. Descarga AnythingLLM Desktop e instálalo. En la configuración inicial te preguntará qué proveedor de modelos quieres usar: selecciona Ollama. Si Ollama está corriendo en tu máquina —que lo estará, al haberlo instalado antes—, AnythingLLM lo detecta automáticamente. A partir de ese momento, el modelo que descargaste en el paso anterior aparece disponible en el desplegable de la interfaz.
Paso 4. Crea tu primer workspace y empieza a trabajar. En AnythingLLM, crea un workspace nuevo y ponle el nombre de un proyecto actual. Sube un par de documentos —notas, referencias, un texto en proceso, un PDF de investigación— y empieza a conversar con ellos. El modelo leerá tu material y responderá basándose en él.
En total, el proceso desde cero hasta tener el primer workspace funcionando toma entre veinte minutos y una hora, dependiendo de la velocidad de descarga del modelo.
Lo que la IA en local no resuelve (y cómo gestionarlo)
Ser honesto sobre las limitaciones es parte del trabajo. Un modelo local en una máquina de hace unos años puede ser más lento que los servicios en la nube. Las actualizaciones de modelo requieren que tú mismo gestiones las descargas. Y para ciertas tareas muy exigentes —razonamiento sobre problemas altamente complejos, ventanas de contexto extremadamente largas—, los grandes modelos comerciales siguen teniendo ventaja.
Pero aquí aparece una paradoja que vale la pena nombrar: lo que hace apenas seis meses solo era posible en la nube privada de las grandes corporaciones, hoy podemos hacerlo en local y de forma completamente privada. No solo en términos de conversación básica: también en capacidad de razonamiento, en uso de agentes que navegan la web, ejecutan código o gestionan archivos, y en acceso a modelos sin censura que los servicios comerciales nunca ofrecerán. La brecha entre lo que puedes hacer en tu máquina y lo que puedes hacer en la nube se estrecha cada pocos meses, no cada pocos años.
Esto ocurre porque la comunidad de modelos abiertos no para. Investigadores, universidades, empresas y desarrolladores independientes publican constantemente nuevos modelos —muchos de ellos sin filtros de contenido #uncensored— que igualan o superan en tareas concretas a versiones anteriores de modelos comerciales de referencia. Lo que hoy parece una limitación del entorno local es, con frecuencia, un problema que alguien ya está resolviendo y que llegará en la próxima actualización.
La respuesta pragmática mientras tanto es el flujo de trabajo híbrido: usar el modelo local como espacio de trabajo cotidiano —conversaciones de proceso, exploración de ideas, trabajo con documentación propia, borradores— y reservar los modelos en la nube para tareas específicas que requieran capacidades mayores. Ambos entornos son complementarios, no excluyentes.
La soberanía creativa no significa cortar toda conexión con los servicios externos. Significa tener la capacidad de elegir cuándo y para qué los usas, en lugar de depender de ellos por defecto para todo.
Una herramienta, una postura
En hybridart.net no tratamos la IA como una solución neutral ni como un problema a evitar. La entendemos como un campo de fuerzas —económicas, políticas, estéticas— que requiere pensamiento crítico además de destreza técnica. Trabajar con IA en local no es solo una decisión de infraestructura: es también una toma de postura sobre quién controla las herramientas, qué intereses las diseñan y qué territorios del proceso creativo quedan fuera del alcance corporativo.
Esa postura atraviesa buena parte de lo que publicamos. En El régimen de lo invisible: IA, guerra algorítmica y resistencia artística analizamos cómo los sistemas de IA operan como infraestructuras de poder que raramente se hacen visibles, y qué significa para los artistas trabajar dentro —o contra— esa lógica. En Estética artificial: límites, sesgos y la domesticación de la imagen generativa exploramos cómo los filtros y los sesgos de entrenamiento no son accidentes técnicos sino decisiones estéticas y políticas que moldean lo que los modelos pueden —y quieren— producir. En El espacio latente: cartografiar la materia invisible de la inteligencia artificial nos adentramos en la geometría conceptual donde ocurre la generación: el territorio que los modelos locales abren sin restricciones. Y si quieres ir directamente a la práctica, LLM en local para artistas: tu nuevo asistente de estudio, privado y soberano es el punto de entrada más concreto a todo lo que hemos desarrollado en este artículo.
El modelo local es una herramienta. Como toda herramienta, su valor depende de la intención con que se usa y del criterio con que se evalúan los resultados. Pero tener esa herramienta en casa, bajo tu control, sin que nadie más tenga acceso al proceso, cambia la calidad de la relación que puedes construir con ella.
La IA no sustituye el proceso creativo. Lo desplaza, lo acelera y lo obliga a ser más explícito. En local, al menos, ese desplazamiento ocurre en un espacio que es tuyo.